Research
PhD Research
The COVID-19 pandemic profoundly impacted me, inspiring my research journey. I realized that an efficiently trained language model for COVID-19 could rapidly analyze data and offer valuable insights for vaccine development. Motivated by this idea, my research focuses on optimizing language models for specialized domains such as healthcare. My long term vision is to leverage these models for scientific discoveries.
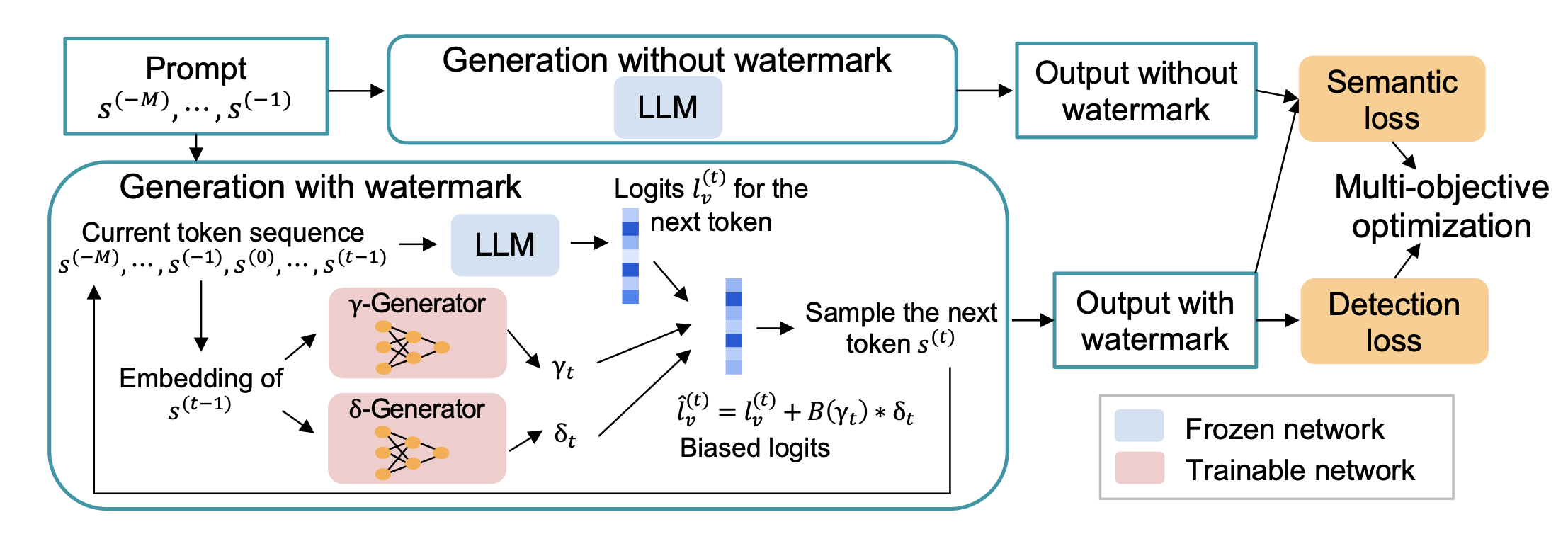
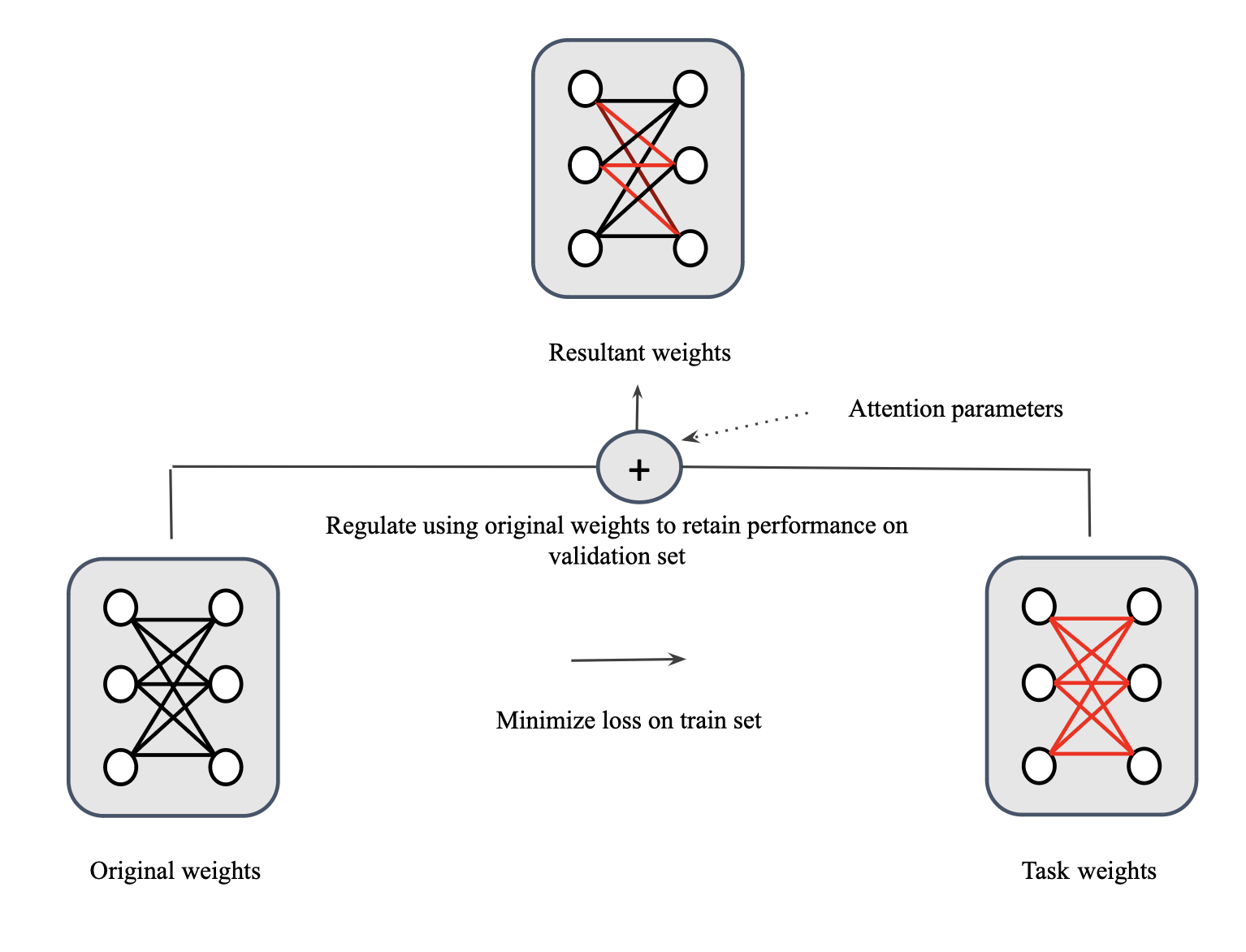
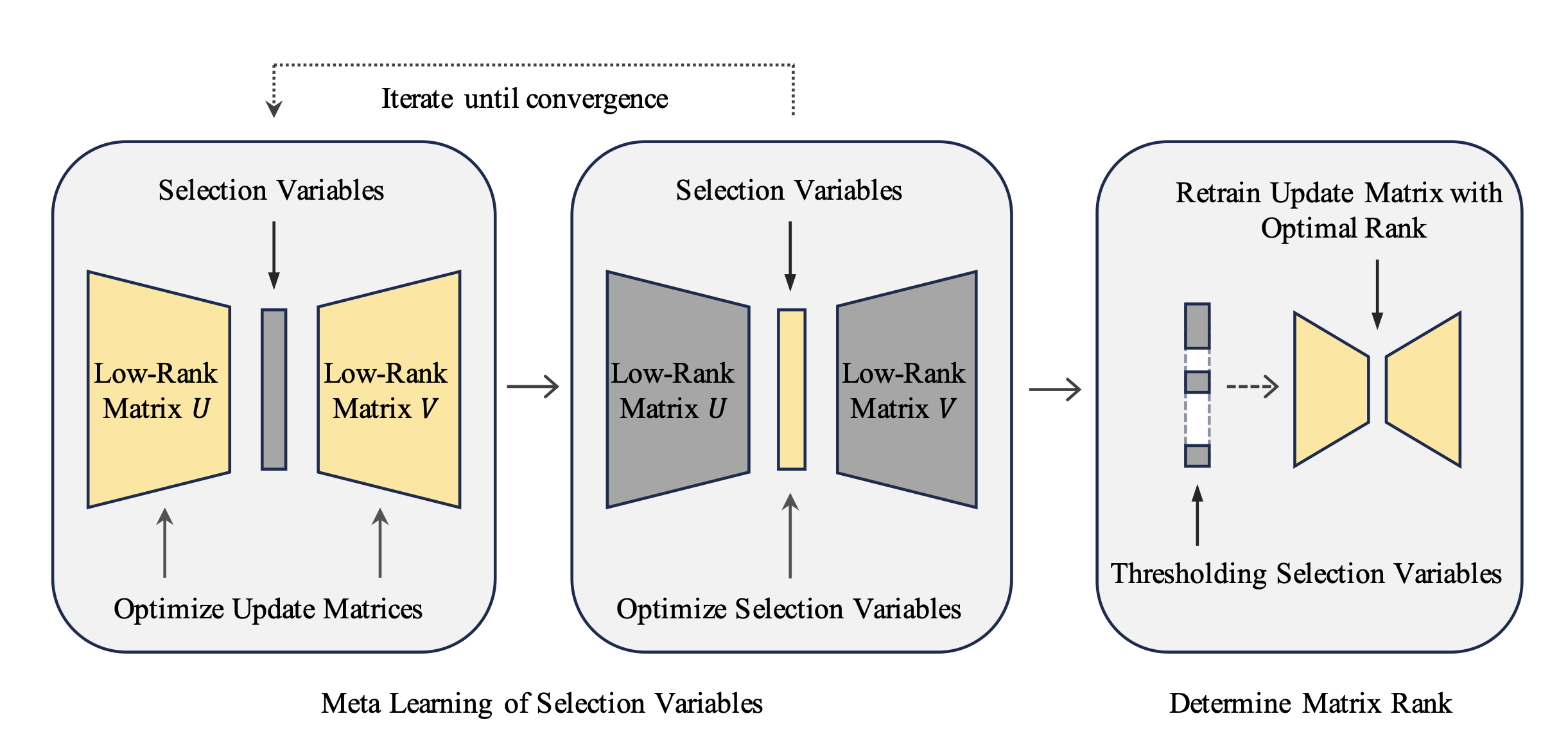
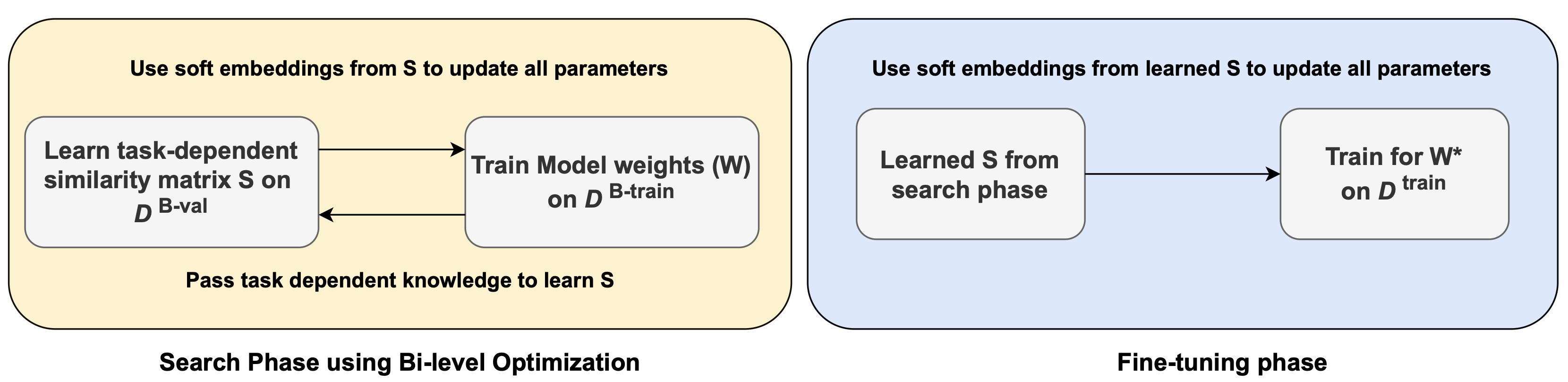
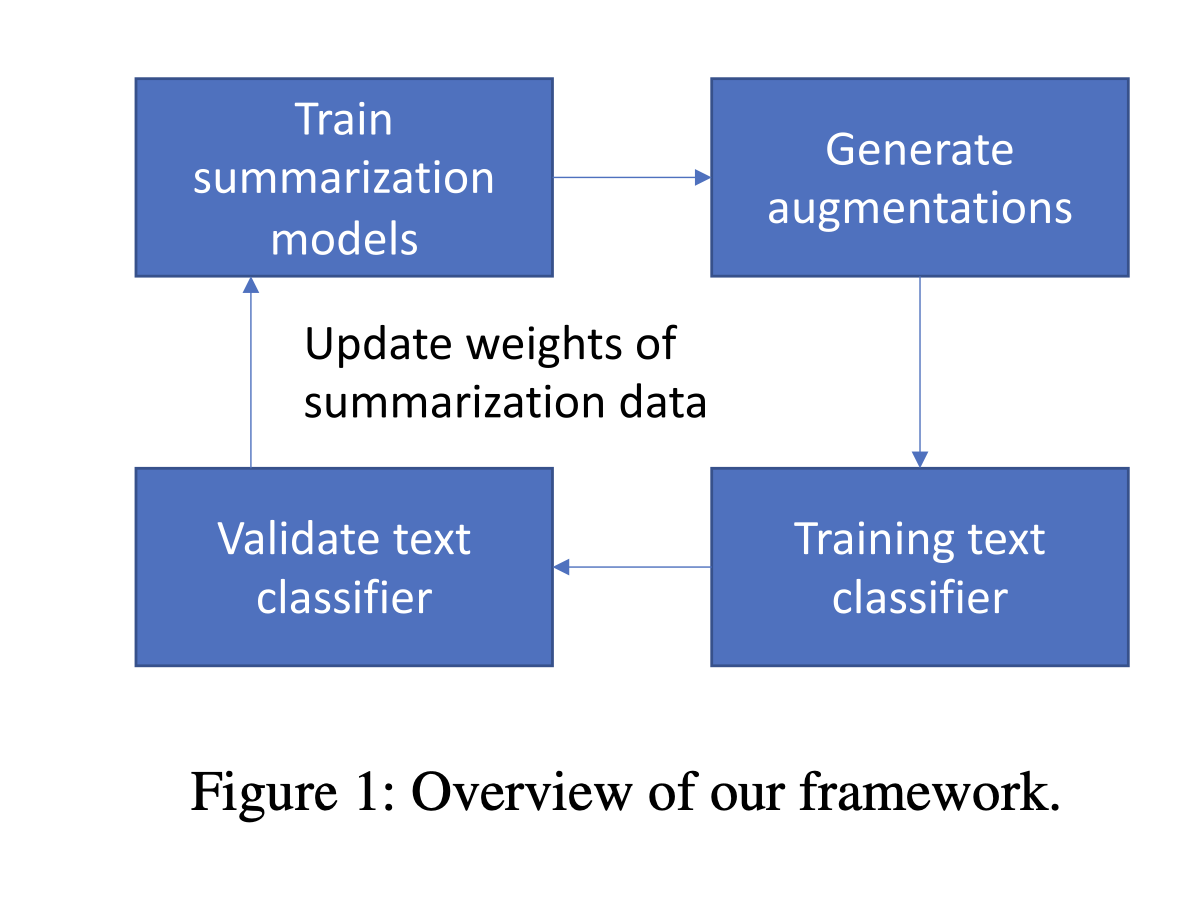
Under this bigger umbrella, I developed methods in synthetic data generation with meta-learning based feedback mechanisms, continual learning in dynamic environments, and the security/safety of large language models. My PhD thesis is available here: [PDF].